
Le Test Driven Development (TDD) ou en français Développement Dirigé par les Tests (DDT) est une technique de développement de logiciel qui préconise d'écrire les tests unitaires avant d'écrire le code source d'un logiciel.
Le cycle préconisé par TDD comporte cinq étapes :
- écrire un premier test ;
- vérifier qu'il échoue (car le code qu'il teste n'existe pas), afin de vérifier que le test est valide ;
- écrire juste le code suffisant pour passer le test ;
- vérifier que le test passe ;
- puis refactoriser le code, c'est-à-dire l'améliorer tout en gardant les mêmes fonctionnalités.
Lors du refactoring, on peut s'aider de plugins Eclipse que sont Elipse-CS (CheckStyle), FindBugs, ECL-Emma basé sur la bibliothèque JaCoCo, pmd4eclipse et SonarQube qui contribuent à améliorer le code en traquant les "mauvaises pratiques".
En plus de la même distribution Eclipse munie de ces plugins, tous développeurs membre d'une équipe doit partager certains réglages du workspace.
Quelques liens sur le Test Driven Development
Kent Beck conçu le cadriciel SUnit, premier framework xUnit. xUnit désigne des outils de test unitaires, déclinés pour divers langages de programmation (SUnit pour Smalltalk ou Squeak, JUnit ou TestNG / httpUnit /jWebUnit pour Java, CppUnit pour C++, OCUnit pour Objective-C, PHPUnit pour PHP, SCLUnit pour SAS/AF et le SAS Component Language, FUTS - Framework for Unit Testing SAS pour les programmes SAS Base et macro, NUnit pour Microsoft .NET, vbUnit pour le Visual Basic, le module unittest de la bibliothèque standard de Python et Jasmine (orientée BDD pour Behavior Driven Development) ainsi que js-test-driver (orientée TDD) pour les scripts Javascript.
Pour les tests sur les composants en Java, PowerMock étend actuellement les framework de mocking (outre JMock) EasyMock et Mockito. Selon le choix fait concernant ces frameworks de mocking, la syntaxe pour écrire un test unitaire diffère légèrement via l'API PowerMock EasyMock ou PowerMock Mockito. Actuellement, PowerMock s'intègre avec les frameworks de tests JUnit et TestNG
Concernant Java : http://www.stepinfo.com/2014/05/tests-unitaires-avec-junit-et-easymock/ Concernant PHP : http://code.tutsplus.com/tutorials/all-about-mocking-with-phpunit--net-27252/
Développement dirigé par les tests et JUnit, EasyMock et Mockitto
Premières utilisations de JUnit
On demande de proposer une application qui permet de gérer une liste de contacts caractérisés par un nom. Les contraintes sur ce contact sont :
- Pas de nom
null; - Pas de nom vide (y compris en ignorant les espaces);
- La taille du nom est comprise entre 3 et 40 ;
Si l'une des trois conditions n'est pas respectée, la création du contact lance une java.lang.IllegalArgumentException.
Un message doit m'avertir lors d'une erreur de saisie, ou si le nom est déjà utilisé (le nom est unique).
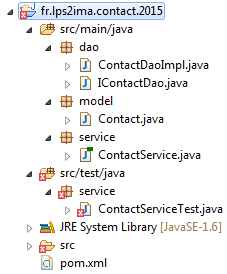
Création du projet Java sous Eclipse
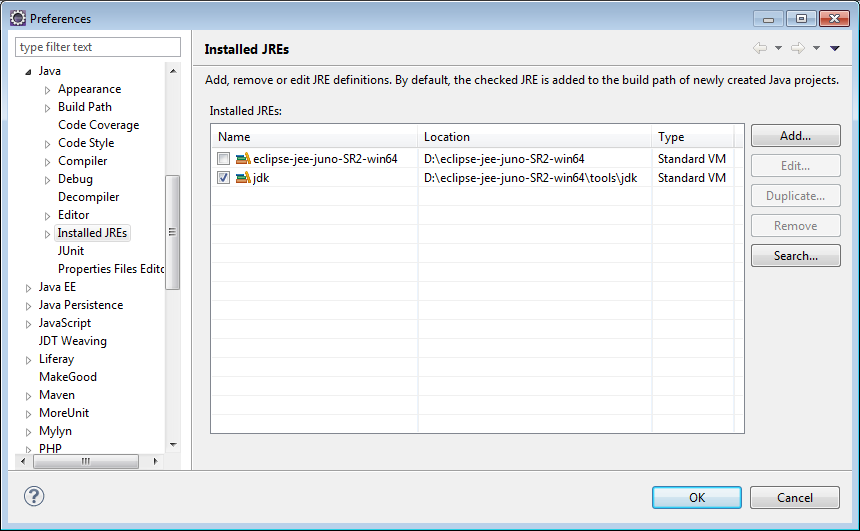
On déclare le JDK 1.6 présent dans \eclipse-jee-juno-SR2-win64\tools\jdk dans notre workspace et on le définit comme environnement par défaut à l'aide du menu Windows > Preferences > Java > Installed JRE >Add... > Standard JVM. On coche la boite à cocher en face du nouvel environnement.
On crée un projet avec le menu New > Project... > Java Project ou directement New > Java Project.
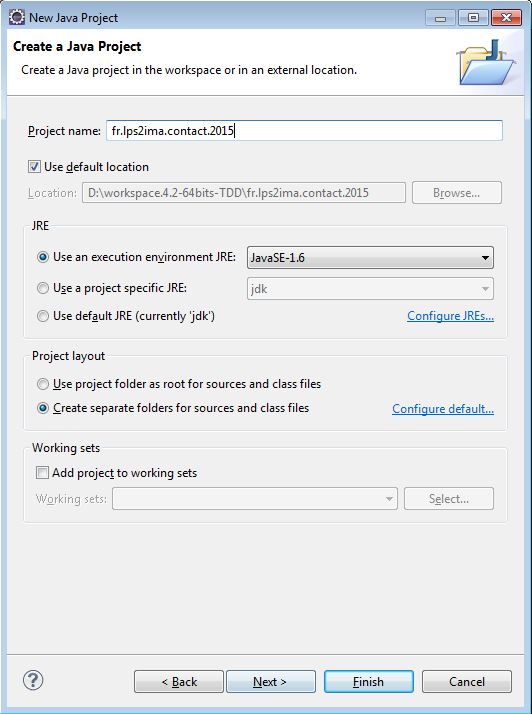
On appuie sur Next.
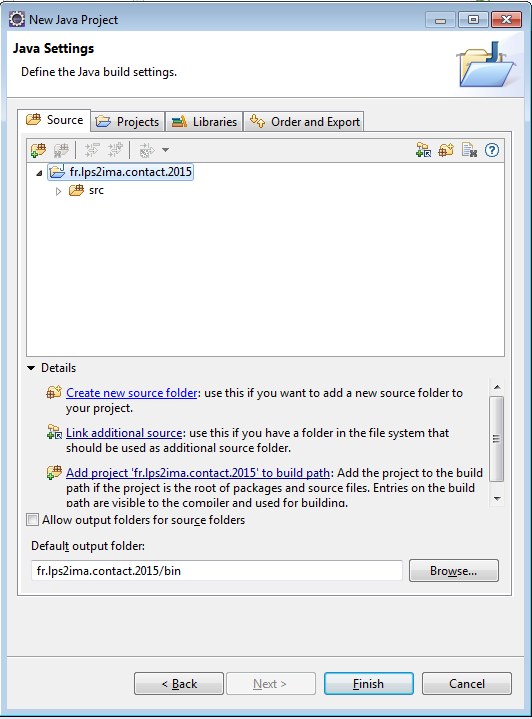
A l'aide du lien Create new source folder, on va créer deux répertoires distincts.

- src/main/java ;
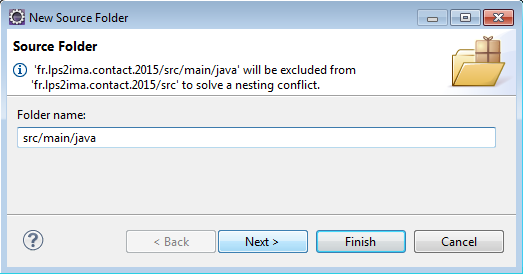
- src/test/java.
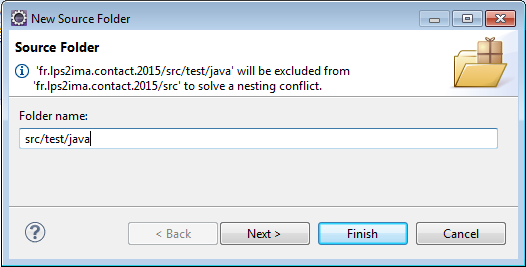
On va retirer le répertoire src du Build Path.
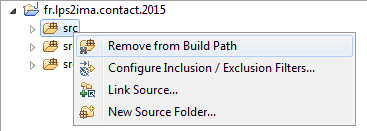
On valide donc l'écran suivant :
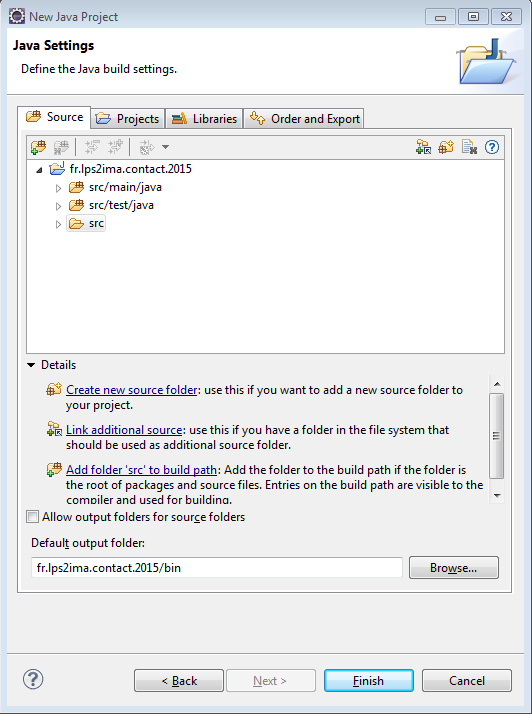
Les classes avant le premier test
On sélectionne dans l'explorateur de projet le répertoire de source src/main/java.
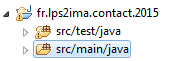
Avec le menu New > Class, on va créer model.Contact :
On complète le squelette généré afin d'obtenir le code suivant :
package model;
import java.io.Serializable;
/**
* Representation objet d'un contact
*
* @author duboism
*
*/
public class Contact implements Serializable {
private static final long serialVersionUID = 1L;
/** Nom du contact */
private String nom;
public String getNom() {
return nom;
}
public void setNom(String nom) {
this.nom = nom;
}
}
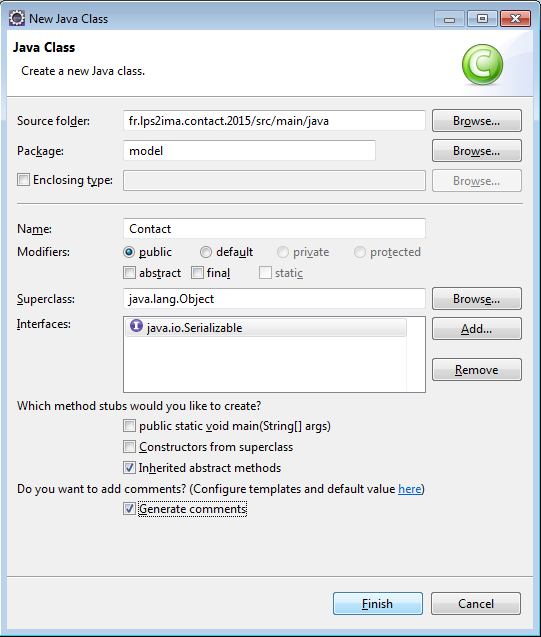
Avec le menu New > Interface, on va créer dao.IContactDao :
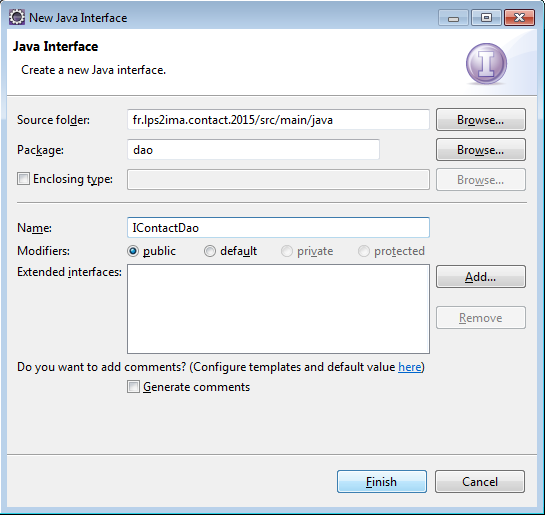
On complète le squelette généré afin d'obtenir le code suivant :
package dao;
import model.Contact;
/**
* Interface du DAO permettant de gérer les contacts
* @author duboism
*
*/
public interface IContactDao {
/**
* Méthode permettant d'insérer en base de données le contact
* @param contact contact a ajouter en base
*/
void creerContact(Contact contact);
}
Avec le menu New > Class, on va créer dao.ContactDaoImpl :
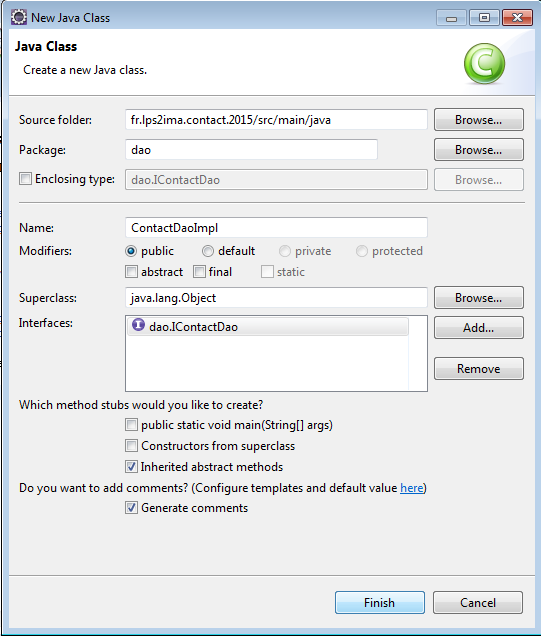
On complète le squelette généré afin d'obtenir le code suivant :
/**
*
*/
package dao;
import model.Contact;
import java.util.ArrayList;
import java.util.List;
/**
* @author duboism
*
*/
public class ContactDaoImpl implements IContactDao {
/**Liste des contacts (base de données en mémoire)*/
private List<Contact> contacts = new ArrayList<Contact>();
/* (non-Javadoc)
* @see dao.IContactDao#creerContact(model.Contact)
*/
@Override
public void creerContact(Contact contact) {
contacts.add(contact);
}
}
Avec le menu New > Class, on va créer service.ContactService :
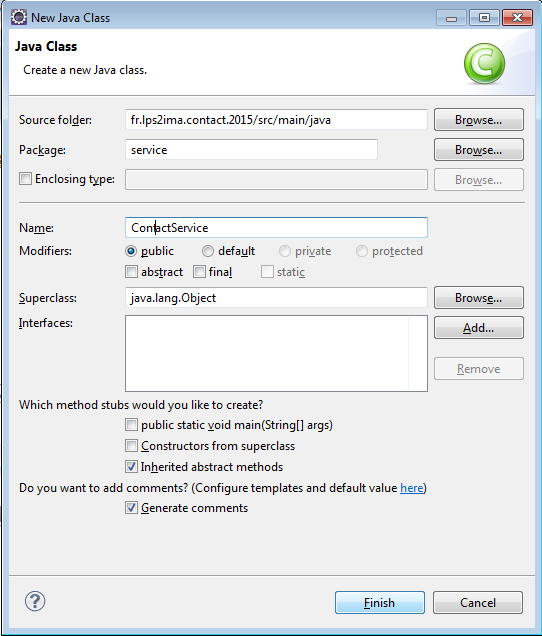
On complète le squelette généré afin d'obtenir le code suivant :
package service;
import model.Contact;
import dao.ContactDaoImpl;
import dao.IContactDao;
/**
* Service de creation de contacts
*
* @author duboism
*
*/
public class ContactService {
private IContactDao contactDao = new ContactDaoImpl();
/**
* Méthode permettant d'ajouter un contact
*
* @param nom
*/
public void creerContact(String nom) {
Contact contact = new Contact();
contact.setNom(nom);
contactDao.creerContact(contact);
}
/**
* Méthode permettant de fixer la classe d'implementation
*
* @param contactDao
*/
public void setContactDao(IContactDao contactDao) {
this.contactDao = contactDao;
}
}
TDD et ses étapes "Rouge, Vert, Refactoriser"
À la question, «Quelles parties de mon logiciel dois-je tester?" l'ingénieur logiciel et expert en tests unitaires Kent Beck a répondu : «Seuls les bits que vous souhaitez voir bien fonctionner..."
Concevoir des tests avant de construire le produit est déjà une manière commune de travailler dans la fabrication de produits du monde réel : les tests définissent les critères d'acceptation du produit. À moins que tous les tests passent, le code n'est pas assez bon. Inversement, en supposant une suite de tests complète, le code est assez bon dès qu'il passe chaque test, et plus aucun travail ne doit être fait à ce sujet. La rédaction tous les tests avant d'écrire un code subirait certains les mêmes problèmes qui ont été trouvés lorsque tous les tests sont effectués après que tout le code ne soit écrit. Les gens ont tendance à être mieux à faire face aux petits problèmes un à la fois, les voir un à la fois, du début jusqu'à la fin avant de changer de contexte pour faire face à un problème différent. Si vous deviez écrire tous les tests pour une application, puis revenir en arrière jusqu'au début et écrire tout le code, vous devez réétudier chacun des problèmes dans la création de votre application deux fois, avec un grand écart entre chaque aller-retour. Se souvenir de ce que vous pensiez quand vous avez écrit un groupe particulier de tests quelques mois plus tôt ne serait pas une tâche facile. Donc dans les faits les développeurs n'écrivent pas tous les tests en premier, mais ils n'écrivent le code qu'après qu'ils ont écrit les tests qui le valideront.
Le principe est donc de coder le test avant d'écrire le code à tester. Mais, comment écrire ce test ? A quoi le test d'un code inexistant devrait ressembler? Regardez le besoin fonctionnel, et demandez-vous, "Si je devais utiliser le code qui a résolu ce problème, comment voudrais-je utiliser ? Écrivez l'appel de méthode que vous pensez être le moyen idéal pour obtenir le résultat. Lui fournir les arguments qui représentent l'entrée nécessaire pour résoudre le problème, et écrivez un test qui spécifie par assertion que la sortie correcte est donnée.
Maintenant, vous lancez le test. Pourquoi devez-vous exécuter le test alors que nous savons tous les deux que ça va rater ? En fait, selon la façon dont vous avez choisi de spécifier l'API, il pourrait même ne pas compiler correctement. Mais même un test en échec a une valeur : cela démontre qu'il y a quelque chose que l'application a besoin de faire, mais elle ne le fait pas encore. Il précise également la méthode qu'il serait bon d'utiliser pour satisfaire le besoin. Non seulement avez-vous décrit le besoin d'une manière à la fois dans répétable et exécutable, mais vous avez conçu le code que vous allez écrire pour répondre à cette exigence. Plutôt que d'écrire le code pour résoudre le problème et ensuite travailler sur comment l'appeler, vous avez décidé ce que vous vouliez appeler, ce qui rend plus probable le fait d'obtenir une API cohérente et facile à utiliser. Par ailleurs, vous avez également démontré que le logiciel ne fait pas encore ce qu'il doit faire. Quand on commence un projet de zéro, ce ne sera pas un surprise.
Mais quand on travaille sur un application qui a hérité d'un code de base compliqué et non pourvu de tests, on peut constater que il est difficile de déterminer ce que le logiciel est capable de faire sur la simple inspection visuelle du code source. Dans cette situation, vous pourriez écrire un test exprimant une fonctionnalité que vous souhaitez ajouter, seulement pour découvrir que le code la prend déjà en charge et donc que le test passe. Vous pouvez maintenant avancer et ajouter un test pour la prochaine fonctionnalité dont vous avez besoin, jusqu'à atteindre la limite des capacités du code existant et que vos tests commencent à échouer.
Les praticiens du développement tiré par les tests se réfèrent à cette partie du processus d'écriture d'un test en échec qui encapsule le comportement désiré du code que vous n'avez pas encore écrit comme l'étape rouge, ou l'étape de la barre rouge. Les environnements de développement populaires, comme Visual Studio et Eclipse montrent une grande barre rouge au dessus de la vue des tests unitaires lorsqu'un des tests échoue. C'est un indicateur visuel évident que votre code ne fait pas encore tout ce que vous avez besoin qu'il fasse.
Bien plus sympa que la barre rouge comme la colère est la sérénité de la barre verte, et ceci est maintenant votre objectif dans la deuxième étape du TDD. Écrivez le code pour satisfaire le ou les tests ne que vous venez d'écrire. Si, pour cela il vous faut ajouter une nouvelle classe ou une méthode, allez-y puisque vous venez d'identifier que cet ajout dans l'API est logique du point de vue de la conception de l'application.
A ce stade, comment vous écrivez le code qui implémente votre nouvelle API n'a pas vraiment d'importance, tant qu'il passe le test. Le code doit être à peine suffisamment bon (Just Barely Good Enough) pour fournir la fonctionnalité. Tout ce qui est "mieux" mais qui n'ajoute pas à vos applications des fonctionnalités est un gaspillage d'efforts sur le code qui ne sera pas utilisé. Par exemple, si vous avez un test unique pour un générateur de salutations, qu'il doit retourner "Bonjour, Bob!" lorsque le nom "Bob" lui est passé, alors ceci est parfaitement suffisant :
- (NSString *)greeter: (NSString *)name {
return @"Hello, Bob!";
}
Faire quelque chose de plus compliqué à ce moment pourrait être inutile. Bien sûr, vous pourriez avoir besoin d'un procédé plus général plus tard; d'autre part, vous ne pourriez ne pas en avoir besoin. Jusqu'à ce que vous écrivez un autre test démontrant la nécessité pour cette méthode de retourner des chaînes différentes (par exemple, que le retour soit "Bonjour, Tim!" lorsque le paramètre est "Tim"), le code fait tout ce que vous savez être ce qu'il a besoin de faire. Félicitations, vous avez une barre verte (en supposant que vous ne pas casser le résultat de tout autre test quand vous avez écrit le code pour celui-ci); votre application est manifestement meilleure qu'elle ne l'était.
Vous pourriez encore avoir des préoccupations au sujet du code que vous venez d'écrire. Peut-être y-a-il un algorithme différent qui serait plus efficace pour encore obtenir les mêmes résultats, ou peut-être votre course pour se rendre à la barre verte ressemble plus une bidouille que vous ne vous sentez pas à l'aise avec. Coller du code écrit ailleurs dans l'application afin de passer le test ou même coller une partie du test dans la méthode devant implémenter la fonctionnalité est un exemple de "mauvais code qui pue" que les applications fraîchement toute vertes ont parfois. Le "code qui pue" est un autre expression inventée par Kent Beck et popularisé dans l'Extreme Programming. Elle se réfère à un code qui peut être OK, mais il y a certainement en son sein quelque chose qui ne semble pas correct.
Maintenant, vous avez une chance de "remanier" l'application et de la nettoyer en changeant l'implémentation sans affecter le comportement de l'application. Parce que vous avez des tests de la fonctionnalité du code écrit, vous serez en mesure de voir si vous cassez quelque chose. Des tests vont commencer à échouer. Bien sûr, vous ne pouvez pas utiliser les tests pour savoir si vous ajoutez accidentellement un nouveau comportement inattendu qui ne touche pas autre chose, mais ceci devrait être un effet secondaire relativement inoffensif parce que rien ne doit utiliser ce comportement. Si elle le faisait, il y aurait un test pour lui.
Cependant, vous pouvez ne pas avoir besoin de refactoriser dès que les tests passent. La principale raison pour le faire tout de suite est que les détails du nouveau comportement sont encore frais dans votre esprit et vous n'avez pas besoin de vous familiariser avec la façon dont le code fonctionne actuellement si vous voulez tout changer.
Donc si vous ne voulez rien changer, c'est bien ! Vous avez gagné. Mais vous pourriez être heureux avec le code juste maintenant Laissez-le tel qu'il est. Si vous décidez plus tard que ce code a besoin de refactoring, les tests seront toujours là et peuvent encore soutenir le travail de refactorisation.
Rappelez-vous, la pire chose que vous pouvez faire est de perdre du temps sur le code de refactoring qui est très bien comme il est.
Alors maintenant, vous avez traversé les trois étapes du développement tiré par les tests : vous avez écrit un test en échec (rouge), vous avez obtenu que le test passe (vert), et nettoyé le code sans changer ce qu'il fait (refactoring) : votre application a un peu plus de valeur à ce stade qu'au début. La micro fonctionnalité supplémentaire que vous venez de produire peut ne pas être une amélioration suffisante pour justifier une livraison (release) à vos clients, mais votre code doit certainement être de qualité release candidate parce que vous pouvez démontrer que vous avez ajouté quelque chose de nouveau qui fonctionne correctement, et que vous n'avez rien de cassé qui avait déjà fonctionné. Il pourrait y avoir des problèmes d'intégration ou d'utilisation, ou vous et le testeur peuvent être en désaccord sur ce qui devait être ajouté. Vous pouvez être sûrs que si vos tests décrivent suffisamment la plage des inputs attendus par votre application, la probabilité d'un bug de logique dans le code que vous venez d'écrire sera faible. Ayant passé du rouge, au vert puis au refactoring, il est temps de revenir au rouge. En d'autres termes, il est temps d'ajouter la prochaine micro fonctionnalité - la prochaine petite exigence qui représente une amélioration à votre développement tiré par les tests se conforme naturellement au génie logiciel itératif, car chaque petite partie du code de l'application est développée avec la qualité de production avant que le travail sur la prochaine partie ne soit démarré. Plutôt que d'avoir une douzaine de fonctionnalités qui ont toutes été commencées mais elles sont toutes incomplètes et inutilisables, vous devez soit avoir un ensemble de cas d'utilisation complètement fonctionnel, soit un seul cas incomplet sur lequel vous êtes encore en train de travailler dessus.
Cependant, s'il y a plus d'un développeur dans votre équipe, vous aurez chacun à travailler sur un cas d'usage différent, mais chacun d'entre vous aurez un problème à résoudre à la fois et une idée claire du moment où cette solution a été achevée.
Quelques précisions sur l'étape de refonte du code(Refactoring) :
Le remaniement (refactoring) consiste à revenir sur le code en permanence pour le rendre plus simple et plus clair et faciliter ainsi l'ajout de nouveau code : cela permet de faire émerger la conception de manière progressive tout au long du développement.
Comment un développeur refond un code ? C' est une bonne question qui surement n'aura jamais de réponse définitive : je pourrais être heureux avec le code que vous détestez, et vice versa. La seule réponse viable est quelque chose comme ceci :
- La refonte du code est nécessaire s'il fait ce que vous avez besoin, mais vous ne l'aimez pas. Cela signifie que vous n'aimez pas son apparence, ou la façon dont il fonctionne, ou comment il est organisé. Parfois, il n'y a pas un signal clair pour la refonte; le code juste "pue".
- Vous avez terminé de le remanier lorsque le code n'a plus mauvaise apparence ou qu'il ne pue plus.
- Le processus de refactoring transforme un mauvais code en un code qui n'est plus mauvais.
Cette description est suffisamment vague pour qu'il n'y ait pas de recette ou de processus que vous pouvez suivre pour obtenir le code remanié. Vous pouvez trouver le code plus facile à lire et à comprendre si vous utilisez un modèle générique orienté objet (Design Pattern) couramment utilisé dans le code qui peut être appliqué dans de nombreuses situations. L'ouvrage sur les design patterns utilisés dans le framework Objectice-C Cocoa écrit par Buck et Yacktman (Cocoa Design Patterns, Addison-Wesley 2009) peut vous aider. Une bonne référence pour les Design Patterns illustrée d'une manière indépendante du langage de programmation est Design Patterns: Elements of Reusable Object-Oriented Software par Gamma, Helm, Johnson, and Vlissides (Addison-Wesley 1995), ouvrage connu sous le nom du livre du Gang of Four. Certaines transformations de code spécifiques sont fréquemment employées dans le refactoring, parce qu'elles rendent le code plus propre. Par exemple, si deux classes implémentent la même méthode, vous pouvez créer une superclasse commune et remonter la méthode dans cette nouvelle classe. Vous pouvez créer une interface pour décrire une méthode que beaucoup de classes doivent offrir. Le livre Refactoring: Improving the Design of Existing Code par Martin Fowler (Addison-Wesley, 1999) propose un grand catalogue de telles transformations, avec des exemples de code en Java.
Le premier test avec JUnit pour le TDD
On sélectionne dans l'explorateur de projet le répertoire de source src/test/java.
Avec le menu New > Class, on va créer service.ContactServiceTest :
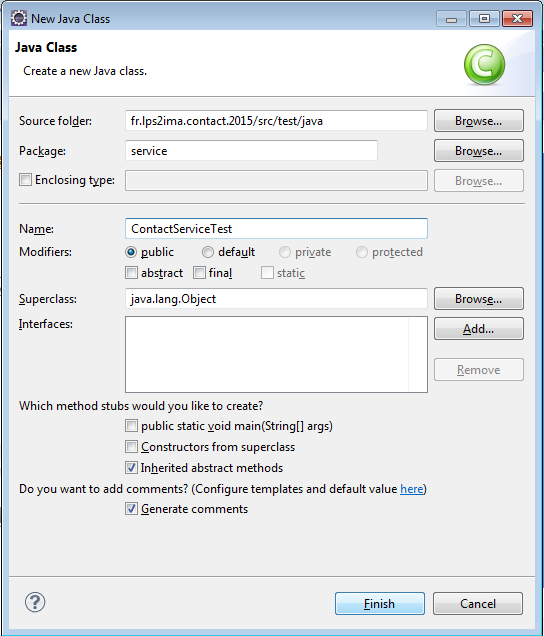
On complète le squelette généré afin d'obtenir le code suivant :
package service;
import org.junit.Test;
/**
* Classe de test du service de contact
* @author duboism
*
*/
public class ContactServiceTest {
/**Service a tester*/
private ContactService service = new ContactService();
/**Vérifie que l'on lève une exception si le nom passé est null*/
@Test(expected=IllegalArgumentException.class)
public void testNomNull() {
service.creerContact(null);
}
}
JUnit permet, depuis la version 4, lutilisation des annotations.
La première chose à savoir, cest que pour déclarer une méthode comme Méthode de test, il suffit de la précéder de lannotation suivante qui permet dans son paramètre expected de préciser l'exception attendue :
@Test(expected=IllegalArgumentException.class)
A noter que la bibliothèque JUnit n'est pas référencée dans le projet, ce qui crée une erreur.
Je crée le fichier pom.xml à la racine du projet.
<project>
<modelVersion>4.0.0</modelVersion>
<name>ContactService</name>
<artifactId>fr.lps2ima.contact.2015</artifactId>
<groupId>fr.lps2ima</groupId>
<version>1.0.0-SNAPSHOT</version>
<properties>
<junit.version>4.11</junit.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.6</source>
<target>1.6</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<inherited>true</inherited>
<artifactId>maven-source-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<id>attach-sources</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<inherited>true</inherited>
<artifactId>maven-javadoc-plugin</artifactId>
<version>2.10.1</version>
<executions>
<execution>
<id>attach-javadocs</id>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Je vais exécuter les phases eclipse-eclipe pour initialiser le fonctionnement de maven et maven-test pour exécuter de manière automatique les tests comme expliqué .
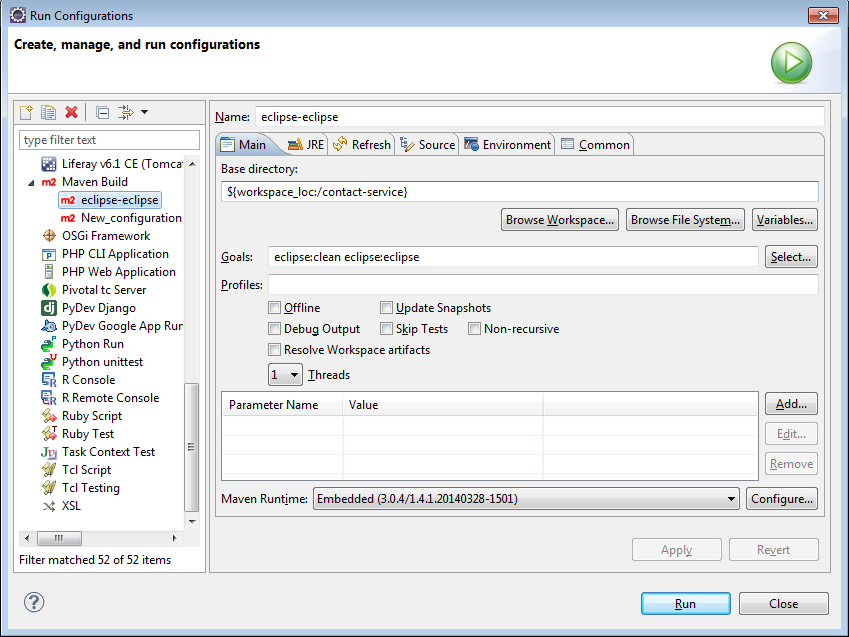
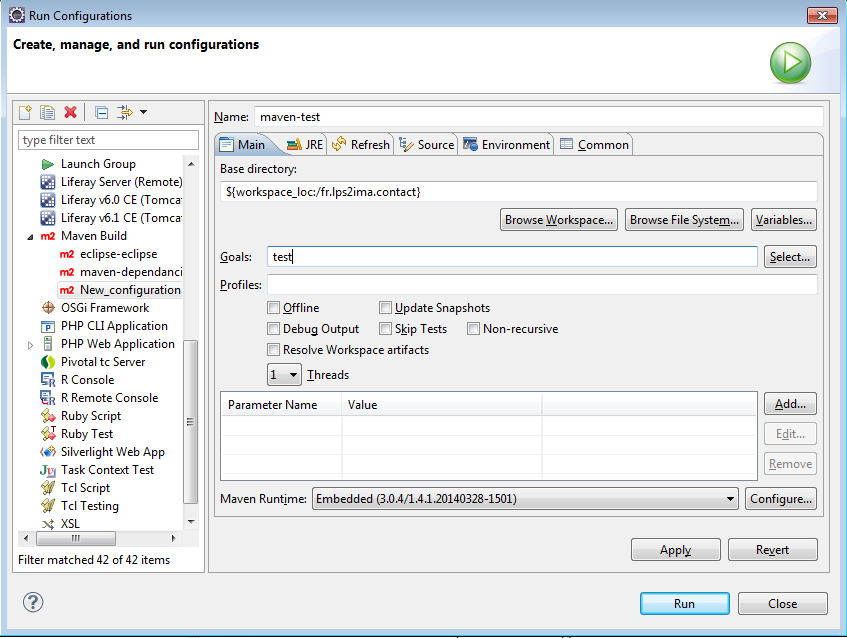
------------------------------------------------------- T E S T S ------------------------------------------------------- Running service.ContactServiceTest Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 0.728 sec <<< FAILURE! Results : Failed tests: testNomNull(service.ContactServiceTest): Expected exception: java.lang.IllegalArgumentException Tests run: 1, Failures: 1, Errors: 0, Skipped: 0 [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 12.514s [INFO] Finished at: Fri Jun 19 12:22:52 CEST 2015 [INFO] Final Memory: 12M/70M [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.10:test (default-test) on project fr.lps2ima.contact.2015: There are test failures. [ERROR] [ERROR] Please refer to D:\workspace.4.2-64bits-TDD\fr.lps2ima.contact.2015\target\surefire-reports for the individual test results. [ERROR] -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
Notons que le test a échoué, ce qui est normal.
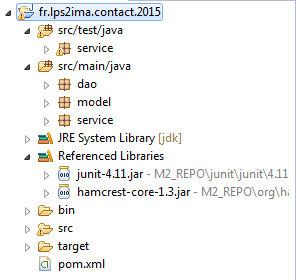
Si on fait rafraichir le projet avec la touche F5, la bibliothèque JUnit avec son prérequis apparait dans les Referenced Librairies.
On peut aussi lancer le test sous Eclipse de manière interactive :
- On sélectionne la classe ContactServiceTest ;
- Menu
Run>Run as>JUnit Test.
Le test va encore échouer, ce qui est toujours normal car je n'ai pas encore codé dans service.ContactService.
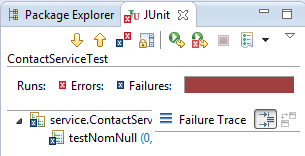
Il nous faut compléter service.ContactService :
public class ContactService {
...
/**
* Méthode permettant d'ajouter un contact
*
* @param nom
*/
public void creerContact(String nom) {
if(nom == null){
throw new IllegalArgumentException("Le nom ne doit pas être null");
}
Contact contact = new Contact();
contact.setNom(nom);
contactDao.creerContact(contact);
}
}
J'exécute le premier test à nouveau et il marche.
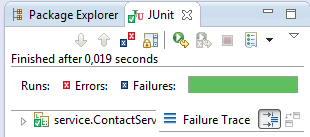
Ceci me permet de passer à un autre test.
Le deuxième test avec JUnit pour le TDD
Je vais tester la longueur du nom (avec espaces ignorés) comprise entre 3 et 40.
Je complète/corrige service.ContactServiceTest :
Je rajoute le premier test de longueur du nom :
service.ContactServiceTest :
...
public class ContactServiceTest {
/**Service a tester*/
private ContactService service = new ContactService();
/**Vérifie que l'on lève une exception si le nom passé est null*/
...
/**Vérifie que l'on lève une exception si le nom passé est trop court (<3 car)*/
@Test(expected=IllegalArgumentException.class)
public void testNomTropCourt() {
service.creerContact("to");
}
Je lance à nouveau de manière interactive les tests. Si le premier test marche toujours, le nouveau test va échouer, ce qui est toujours normal car je n'ai pas encore codé dans service.ContactService la prise en compte de la taille du nom.
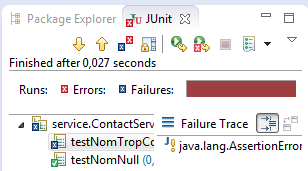
Il nous faut compléter/corriger service.ContactService :
public class ContactService {
...
/**
* Méthode permettant d'ajouter un contact
*
* @param nom
*/
public void creerContact(String nom) {
if(nom == null || nom.trim().length() < 3){
throw new IllegalArgumentException("Le nom ne doit avoir au moins trois caractères");
}
...
}
}
Je relance les tests qui marchent tous maintenant.
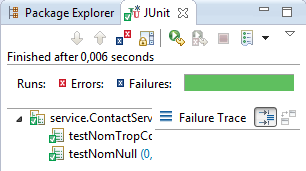
Le troisième test avec JUnit pour le TDD
Je vais tester la longueur du nom (avec espaces ignorés) comprise entre 3 et 40.
Je complète/corrige service.ContactServiceTest pour y rajouter le second test de longueur du nom :
...
import java.util.UUID;
public class ContactServiceTest {
...
/**Vérifie que l'on lève une exception si le nom passé est null*/
...
/**Vérifie que l'on lève une exception si le nom passé est trop court (<3 car)*/
...
/**Vérifie que l'on lève une exception si le nom passé est trop long (>40 car)*/
@Test(expected=IllegalArgumentException.class)
public void testNomTropLong() {
service.creerContact(UUID.randomUUID()+" "+UUID.randomUUID());
}
}
Je lance à nouveau de manière interactive les tests. Si les deux premiers test marchent toujours, le nouveau test va échouer, ce qui est toujours normal car je n'ai pas encore codé dans service.ContactService cette prise en compte de la taille du nom.
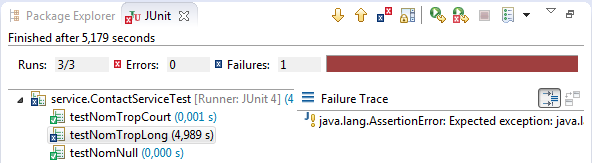
Il nous faut compléter/corriger service.ContactService :
public class ContactService {
...
/**
* Méthode permettant d'ajouter un contact
*
* @param nom
*/
public void creerContact(String nom) {
if(nom == null || nom.trim().length() < 3 || nom.trim().length()>40){
throw new IllegalArgumentException("Le nom doit être compris entre 3 et 40 caractères");
}
...
}
}
Je relance les tests qui marchent tous maintenant.
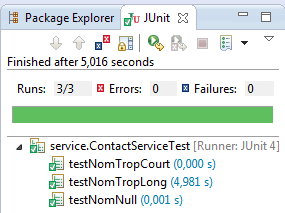
La première refactorisation du code avec JUnit pour le TDD
Après avoir vérifié que tous les tests existants passent, je peux refactoriser le code, c'est-à-dire l'améliorer tout en gardant les mêmes fonctionnalités.
Première amélioration possible : utiliser la bibliothèque apache.commons.lang3.StringUtils qui offre des fonctions de manipulation de chaînes de caractères.
Cette refactorisation de service.ContactService consiste en :
import org.apache.commons.lang3.StringUtils;
...
public class ContactService {
...
/**
* Méthode permettant d'ajouter un contact
*
* @param nom
*/
public void creerContact(String nom) {
int taille = StringUtils.trimToEmpty(nom).length();
if (taille < 3 || taille > 40) {
throw new IllegalArgumentException("Le nom doit être compris entre 3 et 40 caractères");
}
...
}
}
Comme il y a une erreur car la nouvelle bibliothèque n'est pas trouvée dans le projet et qu'elle dépend de commons-collections , il faut rajouter ces dépendances dans le fichier pom.xml :
<project>
<modelVersion>4.0.0</modelVersion>
<name>ContactService</name>
<artifactId>fr.lps2ima.contact.2015</artifactId>
<groupId>fr.lps2ima</groupId>
<version>1.0.0-SNAPSHOT</version>
...
<properties>
...
</properties>
<dependencies>
...
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
...
<build>
...
</build>
</project>
On exécute la phase maven maven-test pour exécuter de manière automatique les tests afin que les bibliothèques soient téléchargées dans le repository local et que le projet les utilisent.
[INFO] Scanning for projects... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building ContactService 1.0.0-SNAPSHOT [INFO] ------------------------------------------------------------------------ Downloading: http://repo.maven.apache.org/maven2/org/apache/commons/commons-lang3/3.4/commons-lang3-3.4.pom Downloaded: http://repo.maven.apache.org/maven2/org/apache/commons/commons-lang3/3.4/commons-lang3-3.4.pom (22 KB at 3.5 KB/sec) Downloading: http://repo.maven.apache.org/maven2/org/apache/commons/commons-parent/37/commons-parent-37.pom Downloaded: http://repo.maven.apache.org/maven2/org/apache/commons/commons-parent/37/commons-parent-37.pom (62 KB at 540.0 KB/sec) Downloading: http://repo.maven.apache.org/maven2/org/apache/apache/16/apache-16.pom Downloaded: http://repo.maven.apache.org/maven2/org/apache/apache/16/apache-16.pom (16 KB at 375.9 KB/sec) Downloading: http://repo.maven.apache.org/maven2/org/apache/commons/commons-lang3/3.4/commons-lang3-3.4.jar Downloaded: http://repo.maven.apache.org/maven2/org/apache/commons/commons-lang3/3.4/commons-lang3-3.4.jar (425 KB at 368.5 KB/sec) [INFO] ------------------------------------------------------- T E S T S ------------------------------------------------------- Running service.ContactServiceTest Tests run: 3, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 5.042 sec Results : Tests run: 3, Failures: 0, Errors: 0, Skipped: 0 [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 14.709s [INFO] Finished at: Fri Jun 19 17:04:54 CEST 2015 [INFO] Final Memory: 11M/111M [INFO] ------------------------------------------------------------------------
Quand on rafraichit le projet, les nouvelles bibliothèques apparaissent :
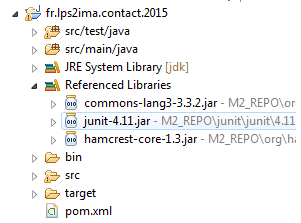
Même si les tests lancés automatiquement marchent, on peut les ré-exécuter à la main.
La deuxième refactorisation du code avec JUnit pour le TDD
Après avoir vérifié que tous les tests existants passent, je peux refactoriser le code à nouveau, c'est-à-dire l'améliorer tout en gardant les mêmes fonctionnalités.
L'amélioration immédiate est l'utilisation de constantes pour les limites de la taille du nom.
Cette refactorisation de service.ContactService consiste en :
...
public class ContactService {
private static final int MAX_SIZE = 40;
private static final int MIN_SIZE = 3
...
/**
* Méthode permettant d'ajouter un contact
*
* @param nom
*/
public void creerContact(String nom) {
int taille = StringUtils.trimToEmpty(nom).length();
if (taille < MIN_SIZE || taille > MAX_SIZE) {
throw new IllegalArgumentException("Le nom doit être compris entre 3 et 40 caractères");
}
...
}
}
Je relance de manière interactive les tests. Ils marchent tous.
A noter qu'il existent des règles d'amélioration de la lisibilité du code. Des plug-ins Eclipse exposé à la fin ont pour objectifs de vous aider à refactoriser le code.
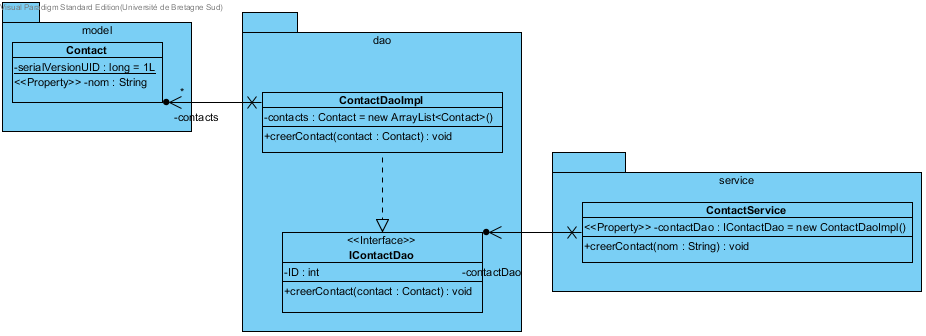
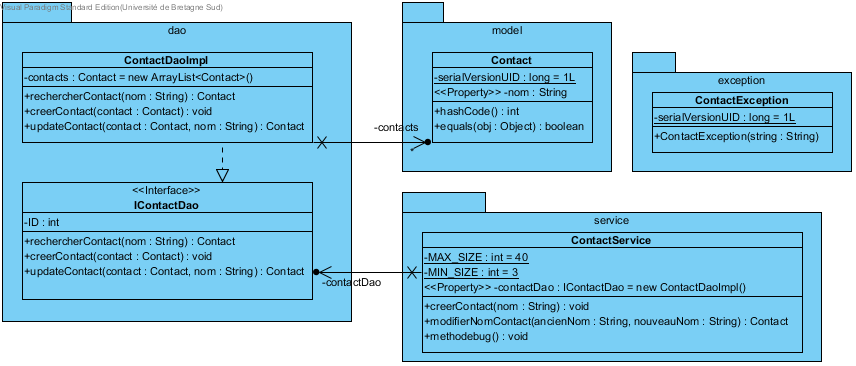
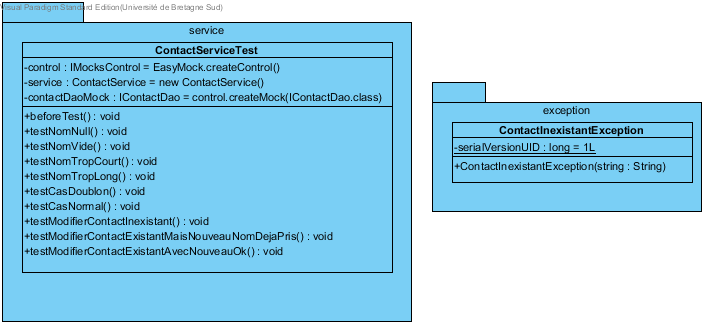
A la fin de cette première partie, le diagramme de classe pour la classe de test est :

Vous pouvez télécharger l'archive du workspace à ce stade dans la mesure ou ni EasyMock, ni Mockitto ne sont encore utilisés.
Workspace du projet sans mocking ( )
)
Tests sur les composants avec EasyMock
Le point de départ de cette partie correspond à l'archive définie ici.
Tests sur les composants avec Mockitto
Le point de départ de cette partie correspond à l'archive définie ici.
service.ContactServiceTest :
import java.util.UUID;
...
/**Vérifie que l'on lève une exception si le nom passé est trop court (<3 car)*/
@Test(expected=IllegalArgumentException.class)
public void testNomTropCourt() throws ContactException{
service.creerContact("to");
}
/**Vérifie que l'on lève une exception si le nom passé est trop long (>40 car)*/
@Test(expected=IllegalArgumentException.class)
public void testNomTropLong() throws ContactException{
service.creerContact(UUID.randomUUID()+" "+UUID.randomUUID());
}
exception.ContactException :
package exception;
public class ContactException extends Exception {
/**
*
*/
private static final long serialVersionUID = 1L;
public ContactException(String string) {
super(string);
}
}
service.ContactServiceTest :
Ensuite, JUnit propose des méthodes pour tester les valeurs. La méthode la plus couramment utilisée est la méthode assertEquals() qui vérifie que le premier paramètre est bien égal au second paramètre.
service.ContactServiceTest :
service.ContactServiceTest :
import dao.IContactDao;
import exception.ContactInexistantException;
import exception.ContactException;
/**
* Classe de test du service de contact
* @author duboism
*
*/
public class ContactServiceTest {
/**Service a tester*/
private ContactService service = new ContactService();
private IMocksControl control = EasyMock.createControl();
private IContactDao contactDaoMock = control.createMock(IContactDao.class);
@Before
public void beforeTest(){
service.setContactDao(contactDaoMock);
}
/**Vérifie que l'on lève une exception si le nom passé est null*/
@Test(expected=IllegalArgumentException.class)
public void testNomNull() throws ContactException{
service.creerContact(null);
}
/**Vérifie que l'on lève une exception si le nom passé est vide*/
@Test(expected=IllegalArgumentException.class)
public void testNomVide() throws ContactException{
service.creerContact(" ");
}
/**Vérifie que l'on lève une exception si le nom passé est trop court (<3 car)*/
@Test(expected=IllegalArgumentException.class)
public void testNomTropCourt() throws ContactException{
service.creerContact("to");
}
/**Vérifie que l'on lève une exception si le nom passé est trop long (>40 car)*/
@Test(expected=IllegalArgumentException.class)
public void testNomTropLong() throws ContactException{
service.creerContact(UUID.randomUUID()+" "+UUID.randomUUID());
}
/**Vérifie que l'on lève une exception si le nom passé existe déjà en base de données*/
@Test(expected=ContactException.class)
public void testCasDoublon() throws ContactException{
control.reset();
// Appels attendus
Contact contactBase = new Contact();
String nomContactAAjouter = "Doublon";
contactBase.setNom(nomContactAAjouter );
EasyMock.expect(contactDaoMock.rechercherContact(nomContactAAjouter)).andReturn(contactBase);
control.replay();
service.creerContact(nomContactAAjouter);
}
/**Vérifie le cas passant*/
@Test
public void testCasNormal() throws ContactException{
//Remise à 0 des mocks
control.reset();
String nomContactAAjouter = "Arnaud";
// Appels attendus
EasyMock.expect(contactDaoMock.rechercherContact(nomContactAAjouter)).andReturn(null);
Capture<Contact> captureContact = EasyMock.newCapture(CaptureType.FIRST);
contactDaoMock.creerContact(EasyMock.capture(captureContact));
// Fin de la phase d'enregistrement
control.replay();
//Appel du service
service.creerContact(nomContactAAjouter);
control.verify();
//Vérification que l'ensemble des appels ont bien été effectués
Contact contactCapture = captureContact.getValue();
Assert.assertEquals(nomContactAAjouter, contactCapture.getNom());
}
/**Tentative de modification d'un contact qui n'existe pas (ou plus)
* @throws ContactInexistantException
* @throws ContactException */
@Test(expected=ContactInexistantException.class)
public void testModifierContactInexistant() throws ContactInexistantException, ContactException{
control.reset();
String ancienNom = "ancienNom";
// Appels attendus
EasyMock.expect(contactDaoMock.rechercherContact(ancienNom)).andReturn(null);
control.replay();
service.modifierNomContact(ancienNom, "nouveauNom");
}
/**Tentative de modification d'un contact qui existe avec le nom d'un contact déjà existant
* @throws ContactInexistantException
* @throws ContactException */
@Test(expected=ContactException.class)
public void testModifierContactExistantMaisNouveauNomDejaPris() throws ContactInexistantException, ContactException{
control.reset();
String ancienNom = "ancienNom";
// Appels attendus
Contact contactEnBase = new Contact();
contactEnBase.setNom(ancienNom);
EasyMock.expect(contactDaoMock.rechercherContact(ancienNom)).andReturn(contactEnBase);
String nouveauNom = "nouveauNom";
EasyMock.expect(contactDaoMock.rechercherContact(nouveauNom)).andReturn(new Contact());
control.replay();
service.modifierNomContact(ancienNom, nouveauNom);
}
/**Tentative de modification d'un contact qui existe avec le nom d'un contact déjà existant
* @throws ContactInexistantException
* @throws ContactException */
@Test
public void testModifierContactExistantAvecNouveauOk() throws ContactInexistantException, ContactException{
control.reset();
String ancienNom = "ancienNom";
// Appels attendus
Contact contactEnBase = new Contact();
contactEnBase.setNom(ancienNom);
EasyMock.expect(contactDaoMock.rechercherContact(ancienNom)).andReturn(contactEnBase);
String nouveauNom = "nouveauNom";
EasyMock.expect(contactDaoMock.rechercherContact(nouveauNom)).andReturn(null);
Contact contactMisAJour = new Contact();
contactMisAJour.setNom(nouveauNom);
EasyMock.expect(contactDaoMock.updateContact(contactEnBase, nouveauNom)).andReturn(contactMisAJour);
control.replay();
Contact resultat = service.modifierNomContact(ancienNom, nouveauNom);
Assert.assertEquals(nouveauNom, resultat.getNom());
}
}
package exception;
public class ContactInexistantException extends Exception {
}
package model;
import java.io.Serializable;
/**
* Representation objet d'un contact
* @author duboism
*
*/
public class Contact implements Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
/**Nom du contact*/
private String nom;
public String getNom() {
return nom;
}
public void setNom(String nom) {
this.nom = nom;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((nom == null) ? 0 : nom.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (!(obj instanceof Contact)) {
return false;
}
Contact other = (Contact) obj;
if (nom == null) {
if (other.nom != null) {
return false;
}
} else if (!nom.equals(other.nom)) {
return false;
}
return true;
}
}
package dao;
import model.Contact;
/**
* Interface du DAO permettant de gérer les contacts
* @author duboism
*
*/
public interface IContactDao {
/**
* Méthode qui permet de rechercher un contact a partir de son nom
* @param nom nom du contact recherché
* @return contact correspondant, si aucun ne correspond retourne <code>null</code>
*/
Contact rechercherContact(String nom);
/**
* Méthode permettant d'insérer en base de données le contact
* @param contact contact a ajouter en base
*/
void creerContact(Contact contact);
/**
* Mise à jour du nom d'un contact
* @param contact contact a mettre à jour
* @param nom nouveau nom du contact
* @return contact a jour avec le nouveau nom
*/
Contact updateContact(Contact contact, String nom);
}
package dao;
import java.util.ArrayList;
import java.util.List;
import model.Contact;
public class ContactDaoImpl implements IContactDao {
/**Liste des contacts (base de données en mémoire)*/
private List<Contact> contacts = new ArrayList<Contact>();
@Override
public Contact rechercherContact(String nom) {
for (Contact contact : contacts) {
if(contact.getNom().equalsIgnoreCase(nom)){
return contact;
}
}
return null;
}
@Override
public void creerContact(Contact contact) {
contacts.add(contact);
}
@Override
public Contact updateContact(Contact contact, String nom) {
// TODO Auto-generated method stub
return null;
}
}
package exceptions;
public class ContactException extends Exception {
/**
*
*/
private static final long serialVersionUID = 1L;
public ContactException(String string) {
super(string);
}
}
package service;
import model.Contact;
import dao.ContactDaoImpl;
import dao.IContactDao;
import exception.ContactInexistantException;
import exception.ContactException;
public class ContactService {
private IContactDao contactDao = new ContactDaoImpl();
/**
* Méthode permettant d'ajouter un contact
* @param nom
* @throws ContactException si le nom passé est déjà présent en base de données
*/
public void creerContact(String nom) throws ContactException{
if(nom == null || nom.trim().length() < 3 || nom.trim().length()>40){
throw new IllegalArgumentException("Le nom doit être compris entre 3 et 40 caractères");
}
if(contactDao.rechercherContact(nom) != null){
throw new ContactException("Un contact avec le nom "+nom+" existe déjà en base de données");
}
Contact contact = new Contact();
contact.setNom(nom);
contactDao.creerContact(contact);
}
public Contact modifierNomContact(String ancienNom, String nouveauNom) throws ContactInexistantException, ContactException{
Contact contactBase = contactDao.rechercherContact(ancienNom);
if(contactBase == null){
throw new ContactInexistantException();
}
if(contactDao.rechercherContact(nouveauNom) != null){
throw new ContactException("Un contact avec le nom "+nouveauNom+" existe déjà en base de données");
}
return contactDao.updateContact(contactBase, nouveauNom);
}
public void setContactDao(IContactDao contactDao) {
this.contactDao = contactDao;
}
}
il s'occupe de mettre le mock dans le service sans la necessite de creer un setter.
Annotations
@Rule
@Mock
http://richard.jp.leguen.ca/tutoring/soen343-f2010/tutorials/assignment1-java-swing-and-tdd/
Outils de refactoring
Configuration du formateur java
- On appuie sur
Window>Preferences>Java>Code Style>Formatter
- On appuie sur
Import...
- On choisi un fichier de formatage de code, ici
codeFormatter-wa11y.xml.
Vous pouvez télécharger le fichier de configuration du formateur du code java spécifiques au projet Wa11y( ).
).
- On constate que le formateur
Wa11yest sélectionné.
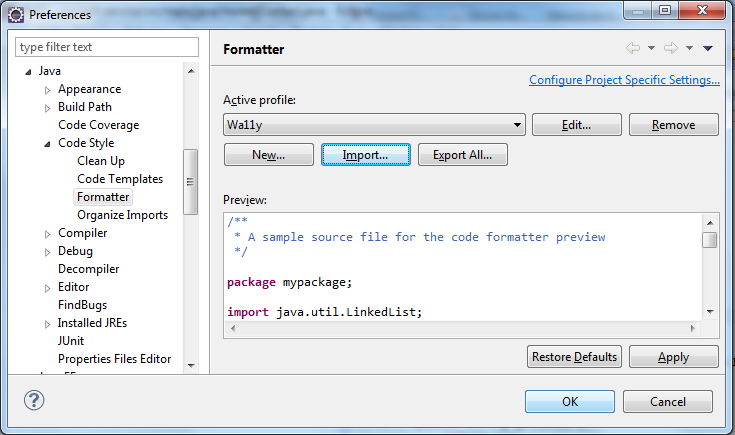
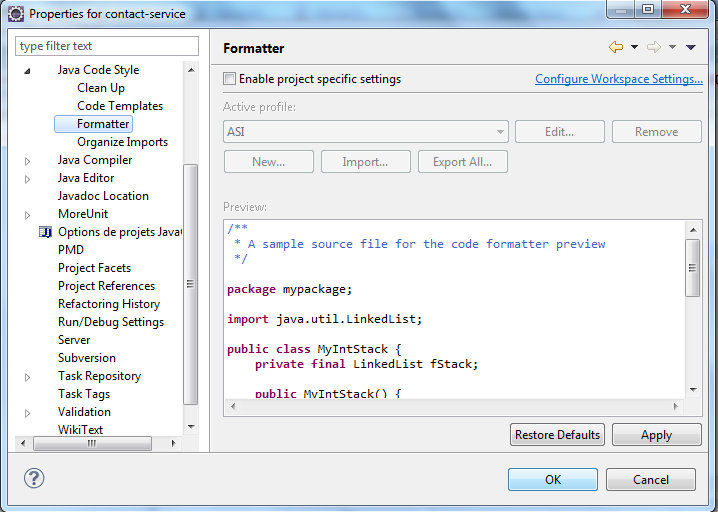
Par défaut, il s'applique à tous les projets du workspace, sauf si on demande à en appliquer un autre en cliquant sur le lien Configure Project Specific Settings... ou si on fait, après avoir sélectionné un projet dans l'explorateur de projets, Clic Droit > Properties > Java Code Style > Formater et on coche Enable Project Specific Settings.
- Il faut aller dans
Window>Preferences>Java>Editor>Save Actions
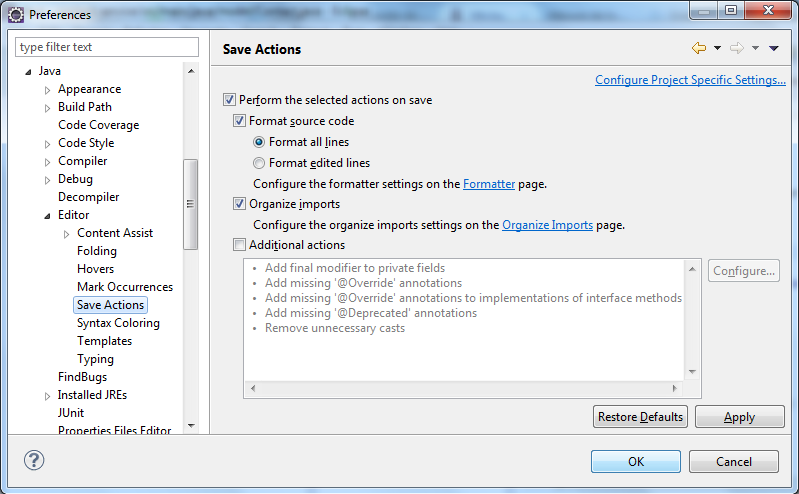
- On coche ce qui est nécessaire.
Plugin Eclipse Eclipse-CS (Checkstyle)
Règles CheckStyle pour une équipe Wa11y
Tous les membres dune équipe du projet wa11y doivent suivre les même règles Eclipse-CS.
Le plugin Eclipse Checkstyle le permet en fournissant lopportunité de faire référence à un fichier de configuration distant pour le paramétrage de checkstyle.
Un fichier de configuration Checkstyle existant peut être importé dans la configuration interne en utilisant le bouton Import .... Notez que ceci écrase la configuration existante. C'est mieux que d'avoir recours à un fichier de configuration externe car le chemin absolu du fichier est conservé, ce qui n'est pas indépendant de la plateforme et/ou du système de fichiers de chaque membre de l'équipe.
- Il faut aller dans
Window>Preferences>CheckStyle
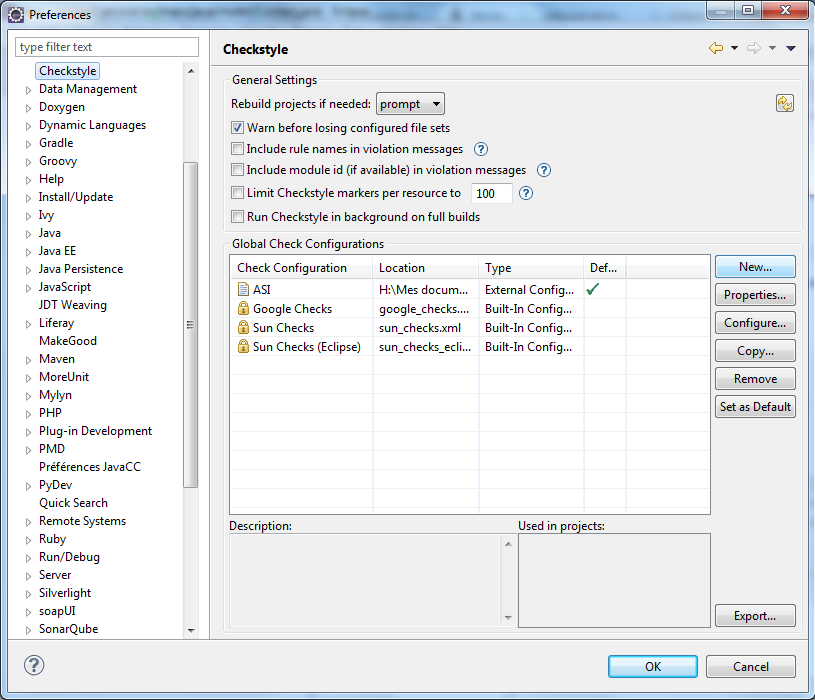
- Il faut appuyer sur le bouton
New....
- Il faut aussi donner un nom à cet ensemble de règles, par exemple
Wa11y. Il faut laisserInternal Configuration Filedans la liste de choixTypeet appuyer sur le boutonImport....
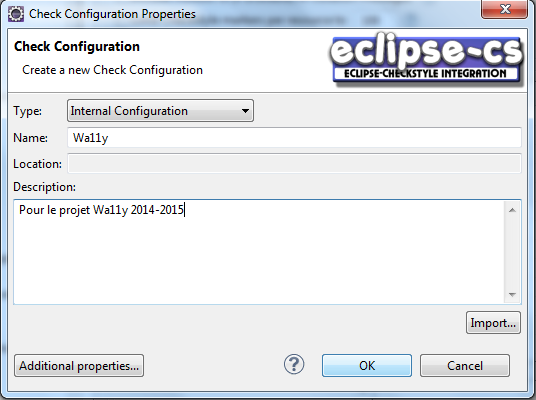
Il faut choisir le fichier de règles CS du projet Wa11y, ici checkstyle-wa11y.xml après avoir choisi Vous pouvez télécharger le fichier de règles CheckStyle spécifiques au projet Wa11y(). Comme il semble sauvegarder dans le paramétrage le chemin absolu du fichier, il vaut mieux
- L'ensemble de règles
Wa11yapparait.

- Il faut le déclarer comme ensemble par défaut en appuyant sur le bouton
.
- Le nouvel ensemble de règles est alors coché.

- On confirme la reconstruction du workspace.
Il faut dans la configuration du projet via Clic Droit > Properties > CheckStyle, il faut cocher CheckStyle active for this project et choisir Wa11y dans la liste de choix.
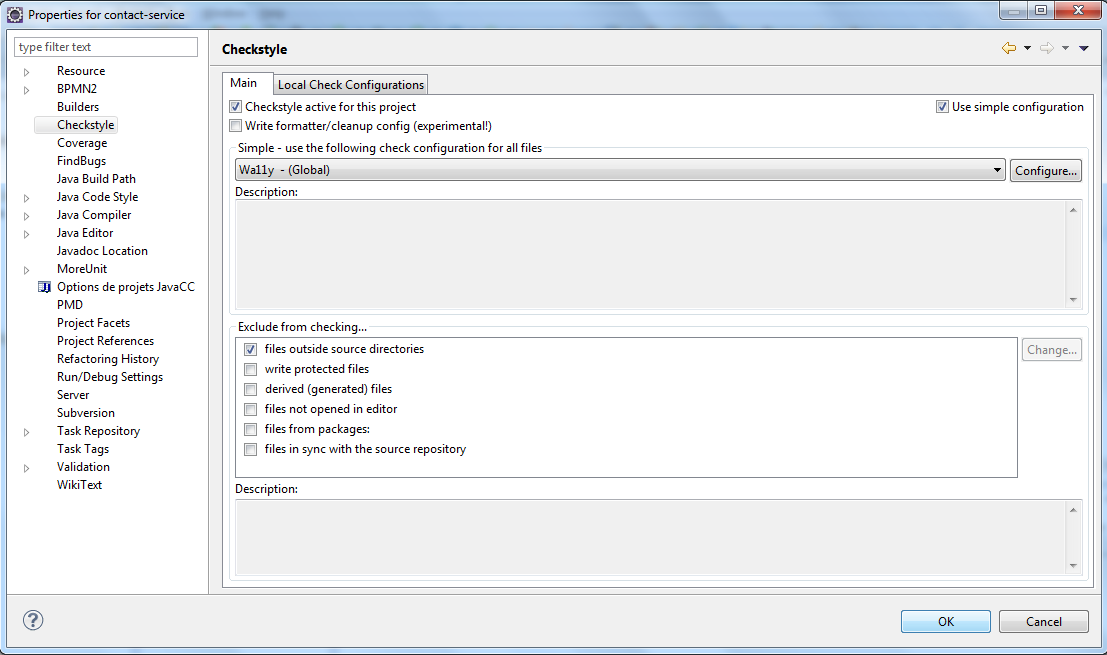
- Il faut confirmer la reconstruction du projet.
Utilisation du Plugin CheckStyle
Le plugin offre 3 nouvelles vues :
Il offre aussi l'entrée du menu contextuel Clic Droit > CheckStyle.
Plugin Eclipse FindBugs
Le fonctionnement de FindBugs est similaire à celui de PMD. FindBugs analyse le code source à la recherche de schémas de codes problématiques. La différence entre FindBugs et PMD tient essentiellement en la nature des problèmes détectés (code qui ne sera jamais exécuté, boucles infinies, détection des potentiels NullPointerException, vulnérabilité du code, performances / usage de la mémoire). De plus, FindBugs travaille sur le bytecode tandis que PMD analyse le code source.
FindBugs peut s'installer en tant que plugin eclipse (URL : http://findbugs.cs.umd.edu/eclipse).
Configuration de Eclipse FindBugs
Pour utiliser des règles identiques au profil Sonar Way d'un serveur SonarQube, il faut les récupérer ou télécharger le fichier de configuration des règles FindBugs du profil de qualité Sonar Way d'un serveur SonarQube version 4.5.2 LTS().
- Il faut ensuite aller dans
Window>Preferences>Java>FindBugspour obtenir les propriétés FindBugs du workspace. - On va sur l'onglet
Filter files.
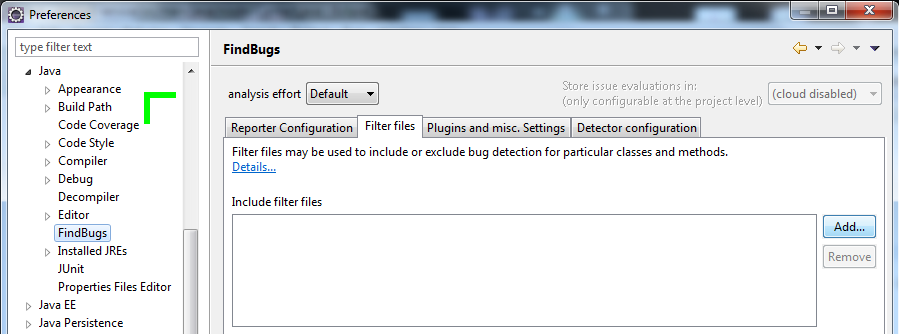
- On utilise le le bouton
Add...au niveau de l'entréeInclude filter files
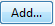
Une fois le fichier choisi, il apparaît.

- Lorsque l'on valide, on nous conseille de recommencer toutes les analyses FindBugs.
Utilisation de Eclipse FindBugs
Une fois le plugin installé et configuré, il suffit de cliquer sur la nouvelle entrée Find Bugs du menu contextuel de l'explorateur de paquetage d'eclipse.
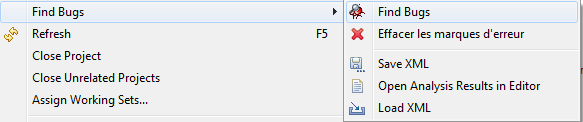
Enfin, il faut passer en perspective FindBugs (Window > Open Perspective > FindBugs)
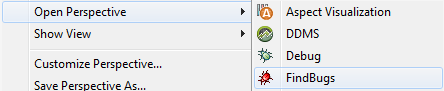
Elle permet d'afficher les vues FindBugs :
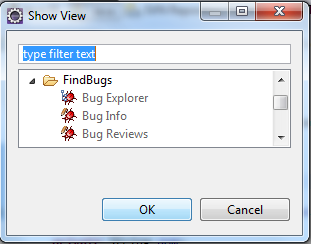
En plus de signaler les potentiels problèmes, FindBugs donne aussi une description du problème et de la manière de le résoudre.
Plugin ECL-Emma basé sur la bibliothèque JaCoCo
La couverture de code est une mesure qui permet de connaitre les lignes de code testées, non testées, ou partiellement testées. Les outils dintégration continue permettent souvent de voir la couverture de code des tests dans un rapport en ligne. Mais ne serait-ce pas mieux de pouvoir consulter la couverture de son code avant même de lavoir poussé dans le gestionnaire de source ? Pour faire cela dans Eclipse, il faut installer le plugin EclEmma.
EclEmma est le plugin Eclipse initialement inspiré de la librairie Emma (doù son nom) mais qui repose aujourdhui sur la librairie JaCoCo.
Ce plugin ne contrôle pas la pertinence des tests mais donne un indicateur sur les branches non testées.
La configuration du plugin pour le workspace est accessible via Window > Preferences > Java > Coverage.
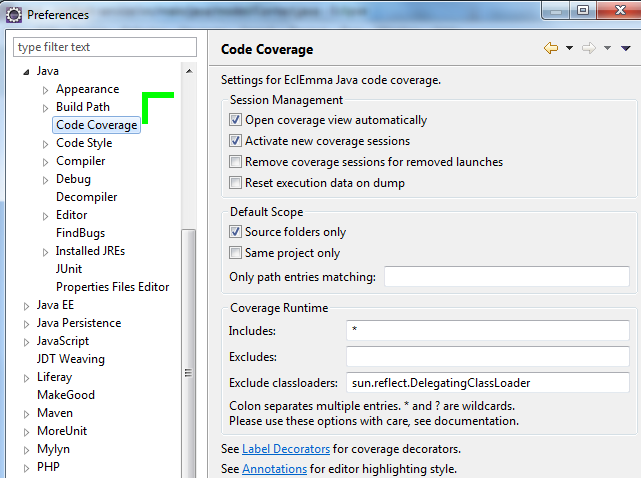
Habituellement, pour lancer vos tests unitaires, jimagine que vous sélectionnez soit un package, soit une classe de tests ou soit un test seul, puis vous faites un Clic Droit > Run As > JUnit Test
Pour lancer le(s) test(s) avec Ecl-Emma afin de vérifier la couverture correspondante, il vous suffit de faire quasiment la même chose. Vous utilisez le nouveau menu Coverage As au lieu du Run As. Notez quil est aussi possible dutiliser un bouton dans lIHM.

En rouge les lignes non couvertes par les tests (il faut donc rajouter des tests !), en jaune les branches partiellement couvertes (il faut aussi rajouter des tests !), et en vert le code/branches totalement couvert.
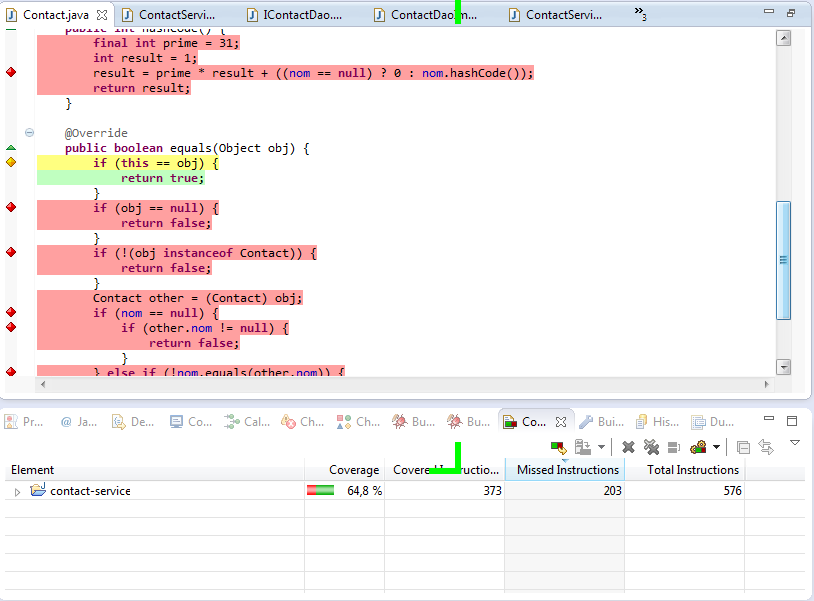
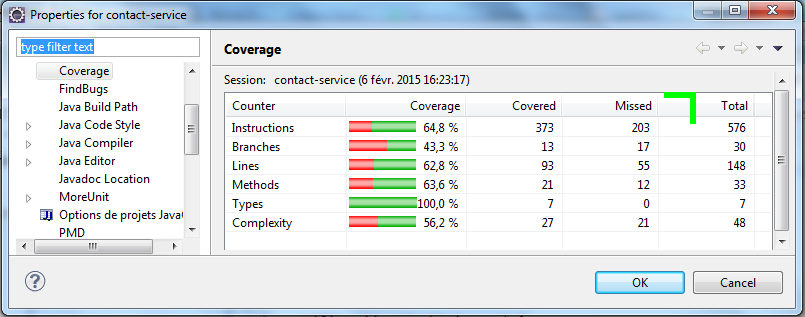
EclEmma fournit deux pourcentages de couverture, celui sur le code de lapplication par les tests (cest celui-ci quil faudra le plus surveiller, cest le plus important), mais aussi le taux de couverture sur les tests eux-mêmes. Ce dernier peut-être utile, car il permet de faire un bon nettoyage dans les tests en montrant les lignes qui ne sont jamais utilisées.
Enfin, si vous regardez les propriétés du projet (Clic Droit > Properties > Java > Coverage), vous pouvez avoir un résumé de la couverture par type délément Java. Ces chiffres sont utiles pour le développeur, le chef de projet, et peuvent faire partie dun livrable client.
Plugins Eclipse PMD
PMD (Programming Mistake Detector ou Project Mess Detector) analyse le code source à la recherche de section de codes connus pour poser problèmes. Ce sont des "anti-pattern", à l'inverse des Design Patterns. Les anti-pattern à rechercher sont configurables et il est possible de n'inclure que ceux qui sont intéressants pour un projet donné. Si FindBugs et PMD ont une intersection non vide, la différence principale est que FindBugs travaille sur le bytecode tandis que PMD analyse le code source.
Il existe deux plugins PMD pour Eclipse. Ils s'installent comme n'importe quel plugin Eclipse par le biais d'une URL (http://sourceforge.net/projects/pmd/files/pmd-eclipse/update-site/ pour le plugin classique pmd4eclipse) à ajouter à la liste connue d'Eclipse pour installer et mettre à jour ses greffons. La dernière version 4.x du plugin est fortement buggée aussi certains préfèrent la dernière version 3.x ou un plugin alternatif nommé eclipse-PMD (http://www.acanda.ch/eclipse-pmd/release/latest).
Les plugins Eclipse PMD permettent de mesurer et de proposer des solutions d'optimisation sur la taille du code, la complexité cyclomatique du code et signale le code inutilisé. Les nouvelles versions tendent à détecter le "code mort".
La complexité cyclomatique d'une méthode est définie par le nombre de chemins linéairement indépendants qu'il est possible d'emprunter dans cette méthode.
Plus simplement, il s'agit du nombre de points de décision de la méthode (if, case, while, ...) + 1 (le chemin principal).
La complexité cyclomatique d'une méthode vaut au minimum 1, puisqu'il y a toujours au moins un chemin. Interprétation
La complexité cyclomatique d'une méthode augmente proportionnellement au nombre de points de décision. Une méthode avec une haute complexité cyclomatique est plus difficile à comprendre et à maintenir.
Une complexité cyclomatique trop élevée (supérieure à 30) indique qu'il faut refactoriser la méthode.
Une complexité cyclomatique inférieure à 30 peut être acceptable si la méthode est suffisament testée.
La complexité cyclomatique est liée à la notion de "code coverage", c'est à dire la couverture du code par les tests. Dans l'idéal, une méthode devrait avoir un nombre de tests unitaires égal à sa complexité cyclomatique pour avoir un "code coverage" de 100%. Cela signifie que chaque chemin de la méthode a été testé.
Installation/désinstallation de la version 4.x en faveur de la version 3
Voici des écrans de la version 4.0.5 de pmd4eclipse lorsque l'on fait :
Window>Preferences>PMD
Window>Preferences>PMD>Rules Configuration
Elle est particulièrement boguée aussi on va la désinstaller.
Help>About Eclipse
- On clique sur
Installation Details - Il faut repérer le plugin PMD dans la liste
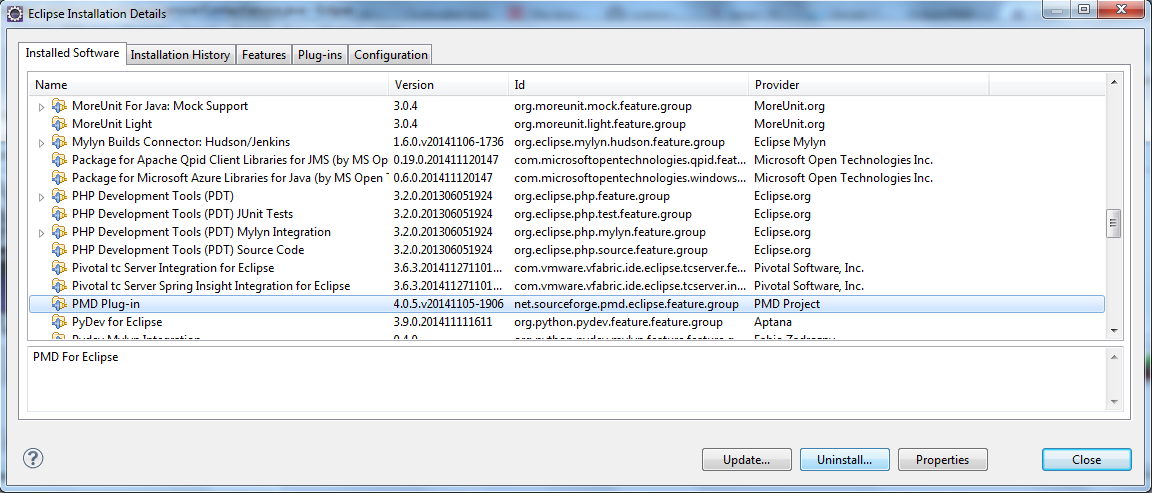
- Il faut le sélectionner et appuyer sur
Uninstall....
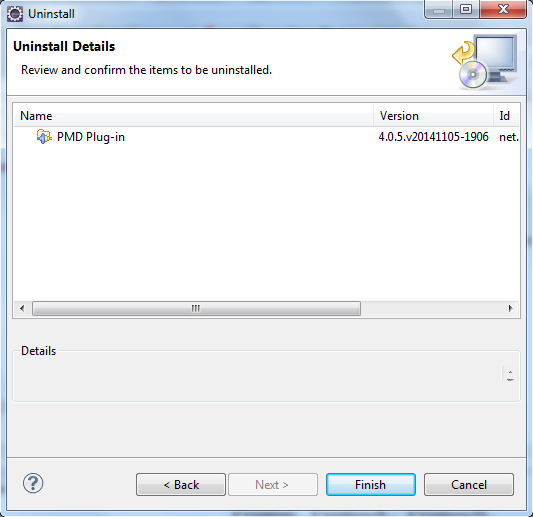
- On confirme la désinstallation avec le bouton
Finish
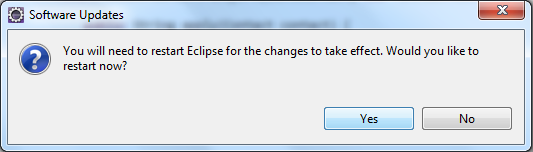
- On accepte de redémarrer Eclipse
On va installer la dernière version de la branche 3.x du plugin pmd4eclipse :
Help>Install New Software...- Il faut entrer l'URL : http://sourceforge.net/projects/pmd/files/pmd-eclipse/update-site/
- Il faut décocher l'option
Show only the lastest versions of available software. - Puis dans la liste, cocher la dernière version de la branche 3 (3.2.6)
- Et appuyer sur le bouton
Next>.
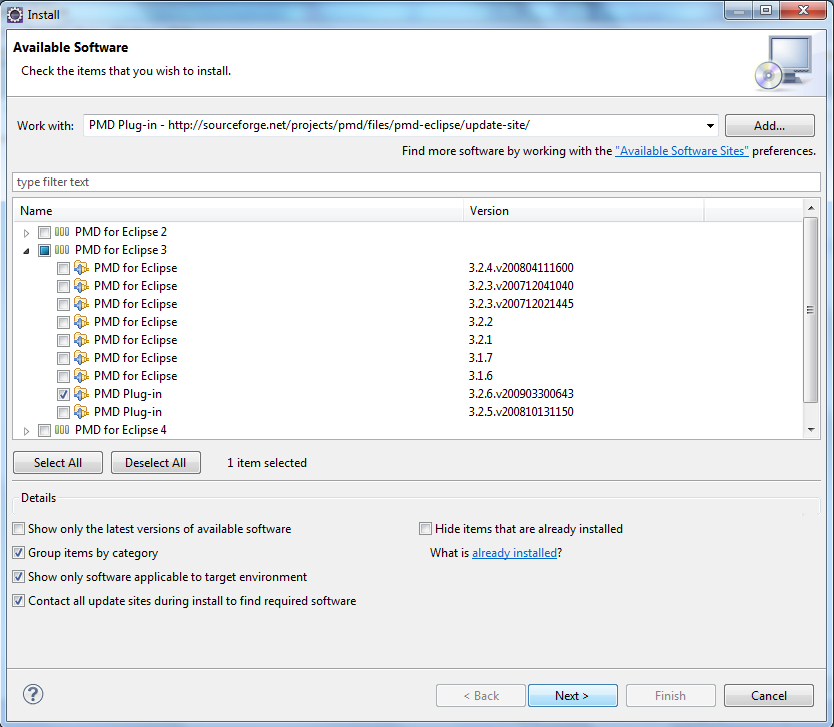
- On valide l'installation
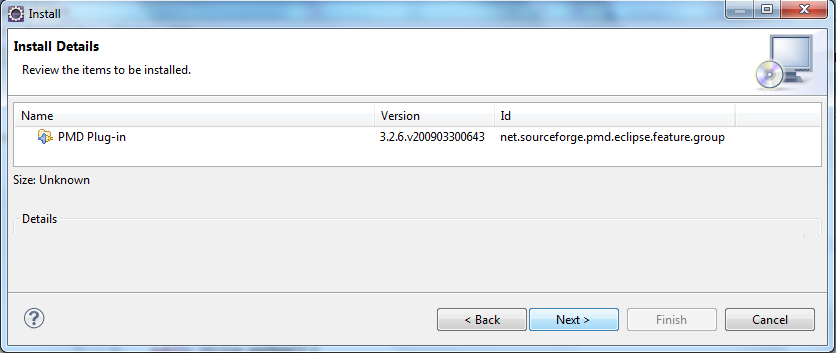
- On accepte la licence
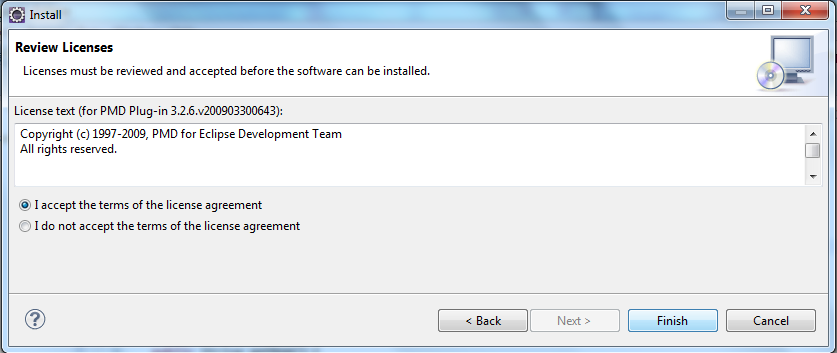
- On fait confiance
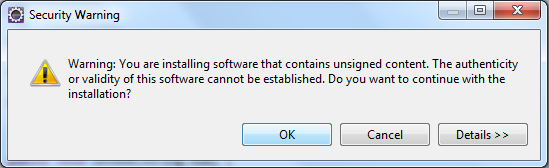
- On accepte de redémarrer Eclipse
Configuration du plugin classique pmd4eclipse
PMD se configure à l'aide d'un seul fichier XML pour le plugin Eclipse. A part pour le plugin Eclipse, le seul pré-requis est donc que ce fichier se trouve dans le CLASSPATH (différents emplacements où la machine virtuelle Java recherche les classes des objets qu'elle doit instancier) pour que PMD le charge et tienne compte de la configuration qui y est décrite. Ce fichier XML est un ruleset, c'est-à-dire, un ensemble de règles... Il est même possible de créer des règles personnelles.
Généralement, il est bien commode de ne disposer que d'un seul fichier pour configurer PMD. Dans certains cas d'utilisation, comme au sein d'Eclipse, il n'est pas possible d'utiliser plusieurs fichiers (Il faut les importer un à un, ce qui est prohibitif). Néanmoins, il est plus pratique et structurant de disposer de plusieurs fichiers pour maintenir aisément ses règles. L'édition de ces dernières se fait généralement dans plusieurs fichiers, chacun regroupant un thème. Si le plus simple est de conserver les règles dans différents fichiers, on peut ensuite générer un fichier unique, les regroupant toutes, à l'aide d'une simple transformation XSLT (voir ce lien). Si installer et configurer PMD dans Eclipse ne prend pas beaucoup de temps, il faut noter que définir, structurer et outiller un référentiel complet et pertinent de règles de qualité pour un ou plusieurs projets demande plus de temps et une certaine expertise.
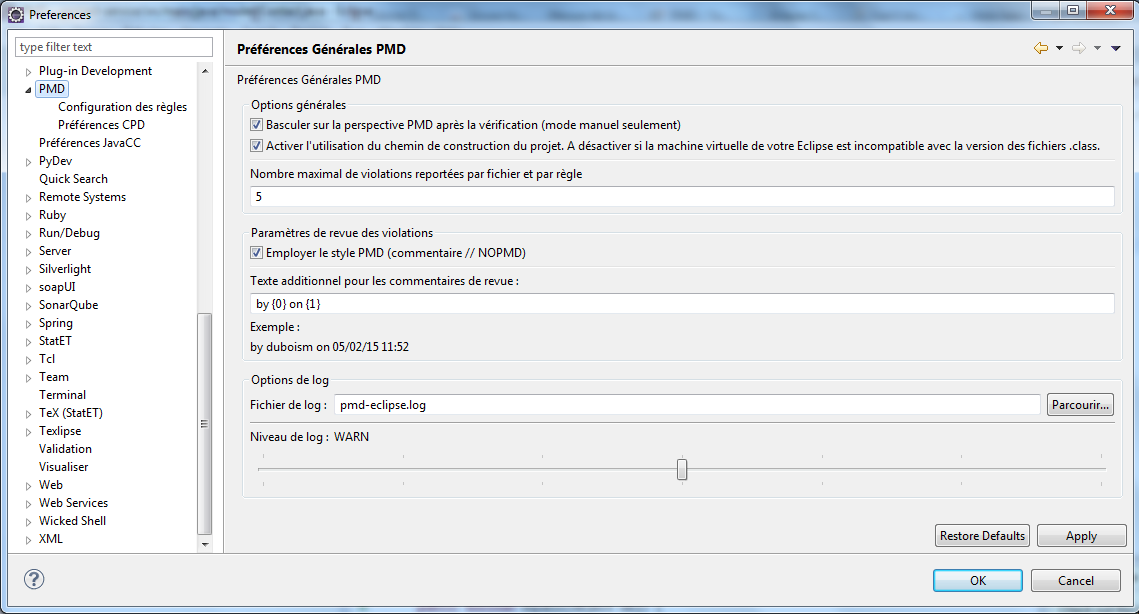
Au niveau de la configuration du workspace, la commande Window > Preferences > PMD permet d'afficher l'écran :
La commande Window > Preferences > PMD > Rules Configuration donne accès à la gestion des règles.
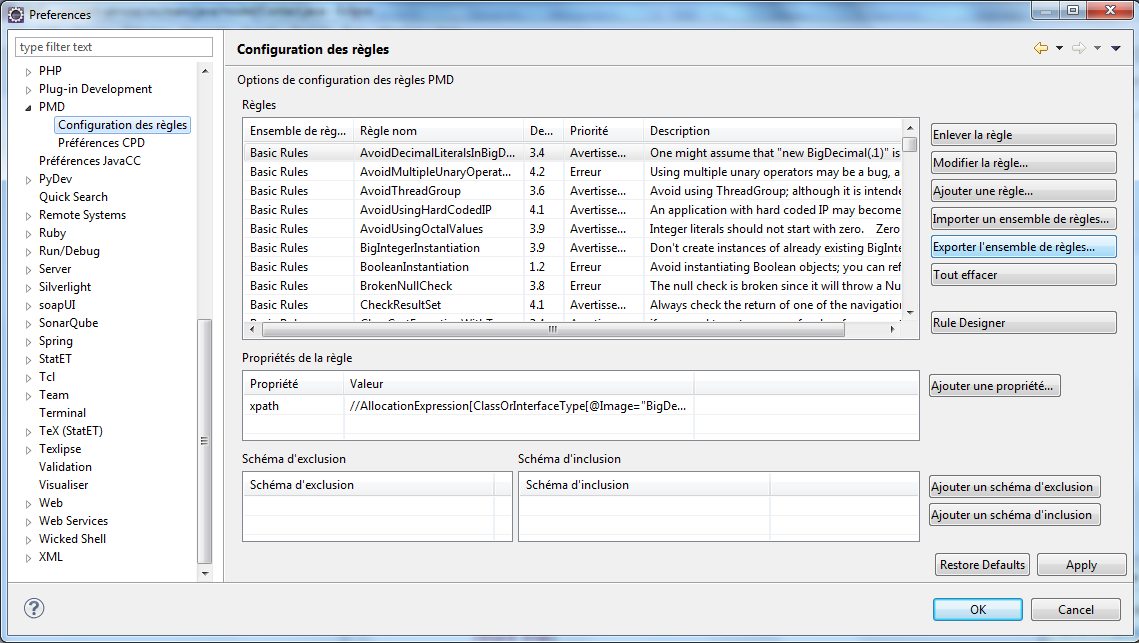
Avant de commencer la personnalisation, il peut être une bonne idée de sauvegarder la configuration existante.
Window > Preferences > PMD > Rules Configuration > Export Rules Set

On désigne le fichier de sauvegarde
On précise la description de cet ensemble de règles
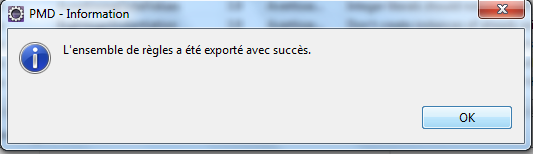
On reçoit confirmation que l'exportation s'est bien passée.
On ne va garder qu'un sous ensemble de règles.
- On appuie sur le bouton
Clear All.

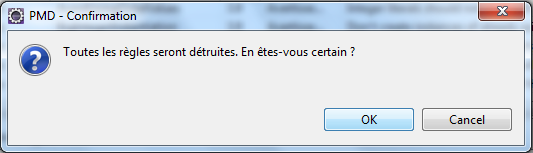
- On confirme la supression des règles existantes
- On appuie sur (
Window>Preferences>PMD>Rules Configuration>)Import Rules Set

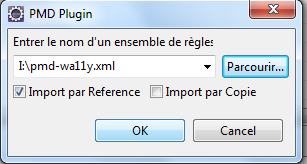
On choisi le fichier d'ensemble de règles au format xml, ici wa11y-pmd.xml en cochant Import by reference. Vous pouvez télécharger le fichier de configuration des règles PMD spécifiques au projet Wa11y au format PMD ruleset v4.x compatible SonarQube et pmd4eclipse 3.x().
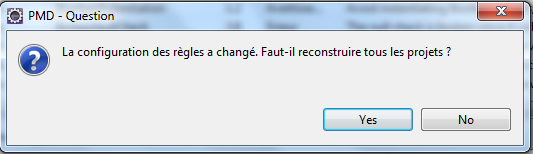
Lorsque l'on quitte l'écran de configuration, on confirme la reconstruction des projets.
Au niveau de la configuration du projet via Clic Droit > Properties > PMD, il faut cocher Activate PMD.
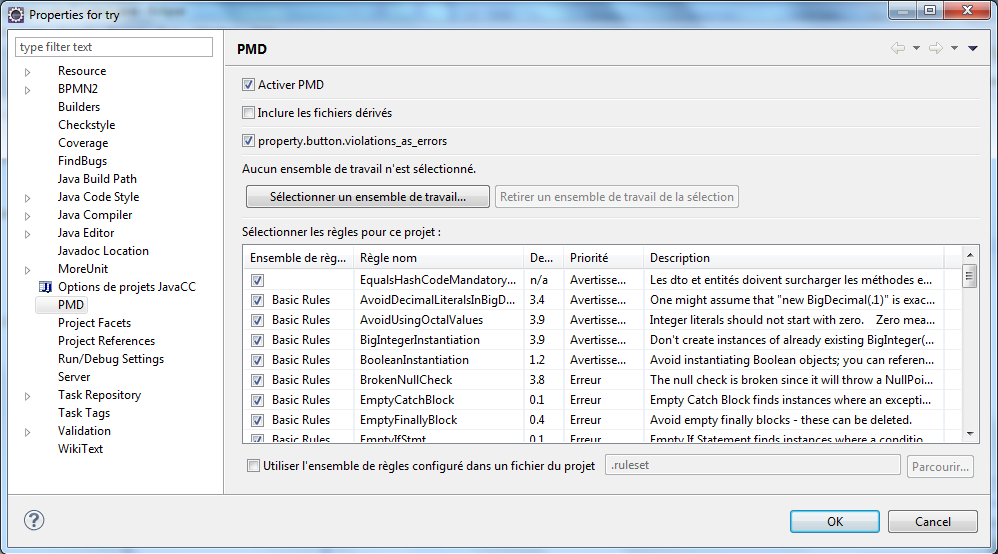
Utilisation du plugin pmd4eclipse
Une perspective PMD est présente.
Elle est constituée de vues PMD :
Ce plugin ajoute aussi une entrée "PMD" au menu contextuel de l'explorateur de paquetage d'Eclipse, disponible avec un Clic Droit.

Il suffit de cliquer sur la sous-entrée "Check code with PMD" de cette nouvelle entrée pour que PMD analyse le code source et ouvre la perspective "PMD".
Dans cette perspective, les erreurs et les avertissements PMD s'affichent à la manière des problèmes de compilation et il devient très facile de les corriger.
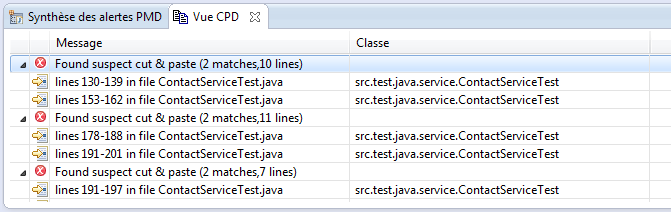
Pour utiliser CPD (Copy and Pastle Detector), faire Clic Droit > PMD > Find suspect cut and paste".
Le rapport nommé notamment cpd-report.txt sera dans le dossier reports du workspace en différents formats.
Voici le rapport est aussi disponible dans la vue CPD :
Plugin Eclipse SonarQube avec un serveur SonarQube local/distant
Le sujet est traité complètement dans d'autres billets. Allez voir ce billet pour l'utilisation de SonarQube dans le contexte renater et ce billet pour une installation dans un contexte complexe.
Un workspace standardisé donc commun pour le projet
Eclipse stocke toute cette configuration dans le répertoire .metadata du workspace. Je vous propose donc de créer un fichier Generic-Metadata.zip pour tous les membres de votre projet afin :
- d'éviter quun membre de léquipe commit en UTF-8, lautre en ISO-8859-1
- d'éviter de reconfigurer la JDK, Checkstyle, PMD, le repo SVN, le proxy de la boite, et une multitude de paramètres à chaque création dun nouveau workspace.
Le but étant que chacun puisse créer son workspace avec une configuration identique et ce en deux clics ! Libre à lui, ensuite, de remettre rose sa couleur de police
Création du fichier
- Créez un nouveau workspace Eclipse.
- Faites tous les réglages que vous souhaitez. Attention, ils doivent être indépendants de la machine. En effet, si vous faites un réglage qui pointe vers
C:\Users\duboismcela risque de mettre à mal la généricité Cest la seule contrainte. - Fermez votre Eclipse.
- Il ne vous reste plus quà zipper le répertoire
.metadataprésent dans le workspace (il ne doit, dailleurs, y avoir que ce répertoire) et placer le fichierGeneric-Metadata.zipsur un répertoire partagé par tout le projet.
Les réglages peuvent être notamment :
- le formateur officiel de lentreprise
- les fichiers de configuration Checkstyle/PMD de lentreprise
- lencodage
- les actions automatiquement lancées à chaque sauvegarde de fichier (organisation des imports, formatage, etc.)
- le dépôt SVN du projet
- le JDK (tous les postes de développement doivent donc lavoir installé de façon homogène)
- le proxy de lentreprise.
Utilisation du fichier
- Créez le répertoire de votre futur workspace à la main (il ne doit pas y avoir de
.metadata). - Dézippez le zip dans ce répertoire (le répertoire
.metadatase trouve maintenant à la base du workspace). - Vous navez plus quà ouvrir votre workspace via Eclipse.
Une distribution commune Eclipse munie du JDK
Il est possible et même conseillé davoir à coté de ce Zip un Eclipse préconfiguré possédant tous les plugins utilisés sur le projet.